- FPGA AI
- Development of ISA Extension for CV32E40P Core on FPGA
- Control and Status Register Map (additional CSRs for User mode)
FPGA AI

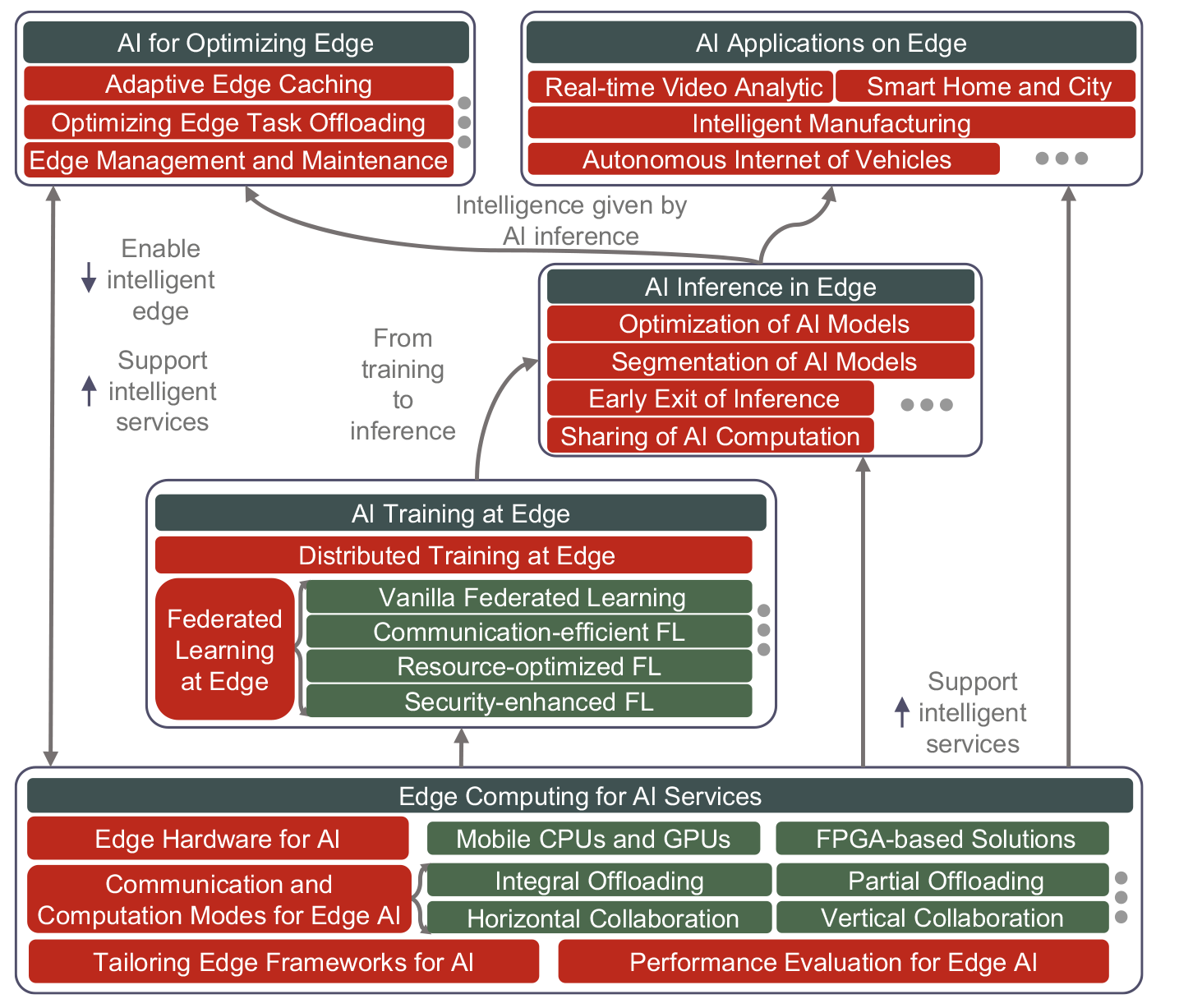
Workflow and Architecture of AI Models on Edge Devices Using FPGA
The diagram provided above outlines a comprehensive framework for deploying AI models at the edge, leveraging various technologies, including FPGAs. Here’s a detailed explanation of the workflow, architecture, and how to connect this system with a Jupyter notebook:
Workflow and Architecture
- Edge Hardware for AI:
- Mobile CPUs and GPUs: General-purpose processors optimized for mobile devices.
- FPGA-based Solutions: Field Programmable Gate Arrays (FPGAs) are crucial for their flexibility, parallel processing capabilities, and low-latency performance, making them suitable for real-time AI inference tasks at the edge.
- Communication and Computation Modes for Edge AI:
- Integral Offloading: Offloading entire tasks to edge devices to reduce latency and network load.
- Partial Offloading: Distributing parts of the computation between the cloud and edge.
- Horizontal Collaboration: Collaboration between multiple edge devices to share computational loads.
- Vertical Collaboration: Integration between cloud and edge for seamless task execution.
- Tailoring Edge Frameworks for AI:
- Developing frameworks that optimize AI models specifically for edge devices, focusing on lightweight and efficient computation.
- Performance Evaluation for Edge AI:
- Metrics and benchmarks to evaluate the performance, such as latency, throughput, and power efficiency.
- AI Training at Edge:
- Distributed Training at Edge: Training AI models across multiple edge devices.
- Federated Learning at Edge: Training models locally on edge devices and aggregating the results, enhancing data privacy and reducing bandwidth usage.
- Vanilla Federated Learning: Basic federated learning approach.
- Communication-efficient FL: Optimizing communication to reduce overhead.
- Resource-optimized FL: Efficiently utilizing hardware resources.
- Security-enhanced FL: Ensuring data security and privacy during the federated learning process.
- AI Inference in Edge:
- Optimization of AI Models: Tailoring models for performance and efficiency on edge hardware.
- Segmentation of AI Models: Dividing models into smaller parts to fit into constrained edge resources.
- Early Exit of Inference: Implementing mechanisms to exit inference early if certain conditions are met, saving computational resources.
- Sharing of AI Computation: Distributing inference tasks across multiple devices.
- AI Applications on Edge:
- Real-time Video Analytics: Using edge AI for immediate video processing.
- Smart Home and City: Enhancing IoT devices with AI capabilities for better automation and control.
- Intelligent Manufacturing: Optimizing production processes with AI-driven insights.
- Autonomous Internet of Vehicles: Enabling vehicles to make real-time decisions based on AI inference at the edge.
- AI for Optimizing Edge:
- Adaptive Edge Caching: Storing frequently accessed data closer to the edge for faster access.
- Optimizing Edge Task Offloading: Deciding which tasks to process locally or offload based on current network and computational load.
- Edge Management and Maintenance: Ensuring the smooth operation of edge devices and systems.
Connecting with Jupyter Notebook
To connect this system with a Jupyter notebook for development, monitoring, and management:
- Setup Environment:
- Ensure you have Jupyter Notebook installed on your local machine or edge device. You can install it using pip:
pip install jupyter
- Ensure you have Jupyter Notebook installed on your local machine or edge device. You can install it using pip:
- Accessing FPGA Resources:
- Use libraries and APIs provided by the FPGA vendor (e.g., Xilinx or Intel) to interface with the FPGA. For example, Xilinx provides PYNQ (Python Productivity for Zynq) which simplifies the interface with Jupyter:
pip install pynq
- Use libraries and APIs provided by the FPGA vendor (e.g., Xilinx or Intel) to interface with the FPGA. For example, Xilinx provides PYNQ (Python Productivity for Zynq) which simplifies the interface with Jupyter:
- Developing and Deploying Models:
- Use Jupyter notebooks to develop AI models using frameworks like TensorFlow or PyTorch.
- Optimize these models for FPGA using vendor-specific tools. For Xilinx, use Vitis AI to optimize and compile models for deployment on FPGA.
from vitis_ai_library import VitisAIModel model = VitisAIModel('model_path.xmodel')
- Inference and Monitoring:
- Perform inference directly from the notebook and visualize results.
result = model.run(input_data) print(result) - Use Jupyter widgets to create interactive dashboards for monitoring the performance and status of the edge devices.
- Perform inference directly from the notebook and visualize results.
- Data Handling and Visualization:
- Collect and preprocess data directly within the notebook.
- Use libraries like Matplotlib, Plotly, or Seaborn for data visualization.
This integration allows seamless development, deployment, and monitoring of AI models on edge devices using FPGA, leveraging the power of in-process execution, efficient hardware utilization, and real-time performance metrics.
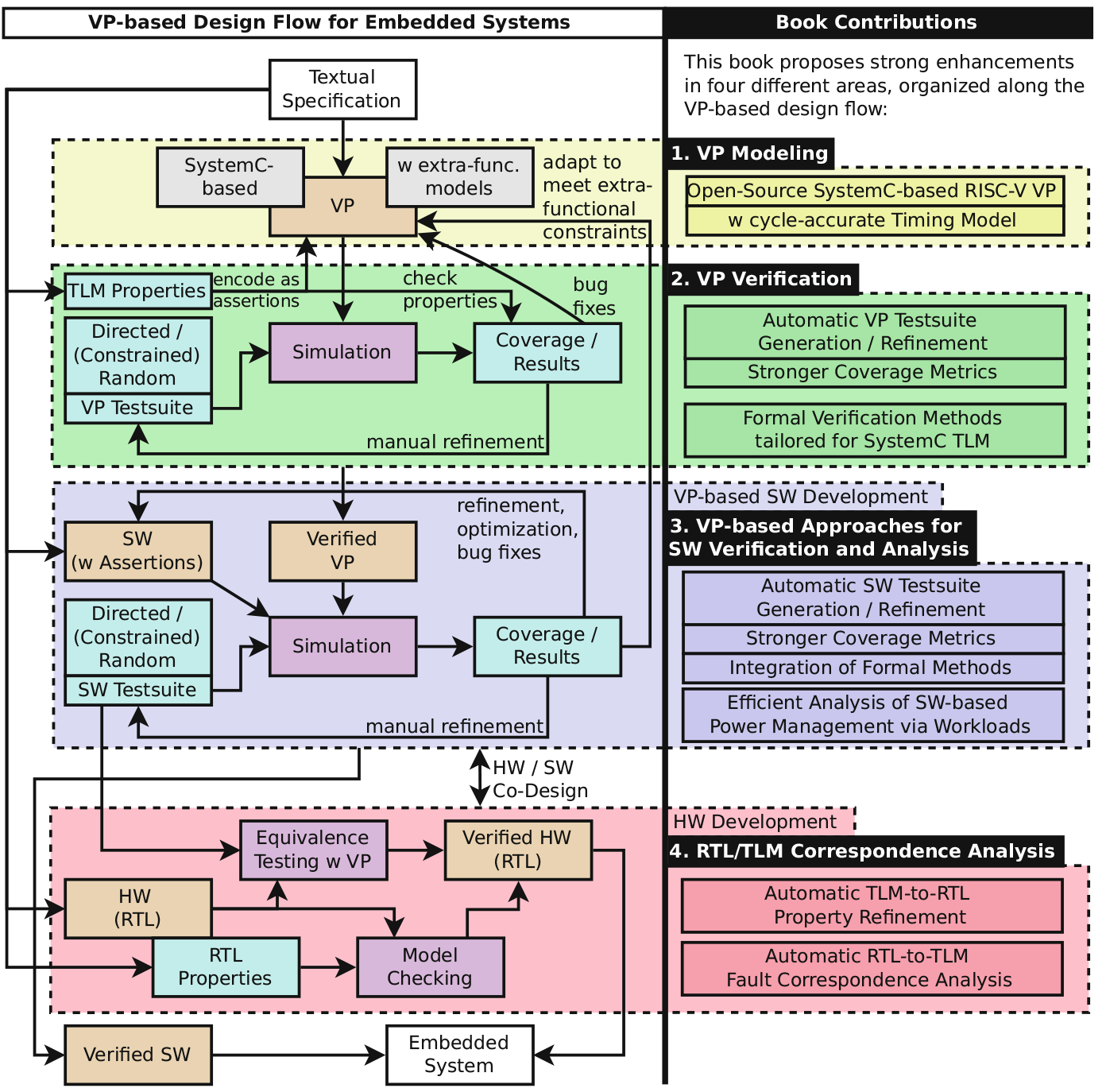
Development of ISA Extension for CV32E40P Core on FPGA
Project Overview
We developed a simple Instruction Set Architecture (ISA) extension to the Open Hardware Group’s CV32E40P core. The main aim was to enhance the core’s performance for AI inference tasks at the edge, specifically targeting low-power applications using the Nexys-A7 FPGA board.
Key Components and Modifications
- ISA Extension:
- We added a subset of 8 instructions from the RISC-V Vector (V) extension to the CV32E40P core.
- These instructions were selected to optimize performance for machine learning inference, particularly for TinyMLPerf benchmarks.
- Auxiliary Processing Unit (APU) Interface:
- The CV32E40P core features an APU interface, similar to the OBI interface, which we used to connect with the accelerator.
- This interface facilitates efficient communication with system memory.
- Core RTL Modifications:
- Modifications were made to the core Register-Transfer Level (RTL) to support the architecture of the accelerator.
- The changes were primarily focused on supporting multi-cycle instructions, which are critical for handling the added vector operations.
- FPGA Development Stages:
- Bitstream Generation: The RTL design, including the core and the accelerator, was synthesized into a bitstream file.
- FPGA Programming: The bitstream was then loaded onto the Nexys-A7 FPGA board.
- Debugging: Binary files were debugged on the FPGA to ensure proper functionality and performance improvements.
Performance Results
The extension and modifications resulted in a more than 5-fold speed-up of the TinyMLPerf benchmark on the CV32E40P core. This significant performance gain demonstrates the potential of using custom ISA extensions for low-energy AI inference at the edge.
Impact and Applications
- Accelerating AI Inference:
- The extended core provides a free and open reference for others looking to accelerate AI inference on low-power devices.
- This work is particularly relevant for edge AI applications, where energy efficiency and performance are critical.
- Educational and Developmental Value:
- The project serves as a valuable educational resource for those interested in FPGA development, RISC-V architecture, and AI acceleration.
- It provides a practical example of how custom ISA extensions can be implemented and evaluated on FPGA platforms.
Conclusion
This project showcases the development and implementation of a custom ISA extension to the CV32E40P core, significantly enhancing its performance for AI inference tasks. The results highlight the feasibility and benefits of extending open-source hardware cores with specialized instructions for targeted applications, especially in energy-constrained environments.
Summary in Korean
ISA 확장 및 FPGA에서 AI 모델 실행을 위한 워크플로우
프로젝트 개요
Open Hardware Group의 CV32E40P 코어에 간단한 명령어 집합 아키텍처(ISA) 확장을 개발하면서 주요 목표를 Nexys-A7 FPGA 보드 에지에서 AI 추론 작업의 성능을 향상하는 것이었습니다.
주요 구성 요소 및 수정 사항
- ISA 확장:
- CV32E40P 코어에 RISC-V 벡터(V) 확장에서 8개의 명령어를 추가했습니다.
- 이러한 명령어는 특히 TinyMLPerf 벤치마크를 위해 머신 러닝 추론 성능을 최적화하기 위해 선택되었습니다.
- 보조 처리 장치(APU) 인터페이스:
- CV32E40P 코어는 가속기와 연결하기 위해 OBI 인터페이스와 유사한 APU 인터페이스를 특징으로 합니다.
- 이 인터페이스는 시스템 메모리와 효율적인 통신을 촉진합니다.
- 코어 RTL 수정:
- 가속기의 아키텍처를 지원하기 위해 코어 RTL(Register-Transfer Level) 수정.
- 이러한 변경 사항은 주로 추가된 벡터 연산을 처리하는 데 중요한 다중 사이클 명령어를 지원하는 데 중점.
- FPGA 개발 단계:
- 비트스트림 생성: 코어 및 가속기를 포함한 RTL 설계가 비트스트림 파일로 합성되었고,
- FPGA 프로그래밍: 비트스트림이 Nexys-A7 FPGA 보드에 로드되어,
- 디버깅: FPGA에서 이진 파일을 디버깅하여 적절한 기능 및 성능 개선을 보장했습니다.
성능 결과
확장 및 수정 결과 CV32E40P 코어에서 TinyMLPerf 벤치마크가 5배 이상 속도가 향상되어 에지에서 저전력 AI 추론을 위해 사용자 정의 ISA 확장을 사용하는 가능성을 입증 하였습니다.
영향 및 응용
- AI 추론 가속화:
- 확장된 코어는 저전력 장치에서 AI 추론을 가속하려는 다른 사람들에게 무료 및 오픈 소스 참조를 제공합니다.
- 이 작업은 에너지 효율성과 성능이 중요한 에지 AI 응용 프로그램과 관련이 있습니다.
- 교육 및 개발 가치:
- 이 프로젝트는 FPGA 개발, RISC-V 아키텍처 및 AI 가속화에 관심이 있는 사람들에게 귀중한 교육 자료를 제공합니다.
- 사용자 정의 ISA 확장이 FPGA 플랫폼에서 어떻게 구현되고 평가될 수 있는지에 대한 실용적인 예를 제공합니다.
결론
이 프로젝트는 AI 추론 작업을 위해 성능을 크게 향상하는 CV32E40P 코어에 사용자 정의 ISA 확장을 개발 및 구현하는 방법을 보여줍니다. 결과는 특히 에너지 제약 환경에서 타겟 애플리케이션을 위해 특수 명령어로 오픈 소스 하드웨어 코어를 확장이 가능함이 증명되어 이를 활용한 실용적 응용분야에서의 새 지평을 열었습니다.
아래 유튜브링크는 사우스햄텬대학의 학부생이 이를 구현한 실예입니다.
에지 특수환경은 일반적인 ML 성능 평가가 불가하고 mlcommons 단체가 정한 규약에 따라야 합니다. 아래는 그 내용입니다.
the benchmarks using TensorFlow Lite for Microcontrollers and Mbed on the reference platform.
We use the EEMBCs EnergyRunner™ benchmark framework to connect to the system under test and run the benchmarks.
We follow the MLPerf Tiny Rules. All MLPerf Tiny benchmarks are single stream only and we do not support the retraining subdivision.
We additionally follow the MLPerf submission and run rules.
docs for openHW
Click to open
| CSR Address | Name | Privilege | Description |
|---|---|---|---|
| User CSRs | |||
| 0x001 | fflags |
URW | Floating-point accrued exceptions. Only present if FPU = 1 |
| 0x002 | frm |
URW | Floating-point dynamic rounding mode. Only present if FPU = 1 |
| 0x003 | fcsr |
URW | Floating-point control and status register. Only present if FPU = 1 |
| 0xC00 | cycle |
URO | (HPM) Cycle Counter |
| 0xC02 | instret |
URO | (HPM) Instructions-Retired Counter |
| 0xC03 | hpmcounter3 |
URO | (HPM) Performance-Monitoring Counter 3 |
| … | … | … | … |
| 0xC1F | hpmcounter31 |
URO | (HPM) Performance-Monitoring Counter 31 |
| 0xC80 | cycleh |
URO | (HPM) Upper 32 bits Cycle Counter |
| 0xC82 | instreth |
URO | (HPM) Upper 32 bits Instructions-Retired Counter |
| 0xC83 | hpmcounterh3 |
URO | (HPM) Upper 32 bits Performance-Monitoring Counter 3 |
| … | … | … | … |
| 0xC9F | hpmcounterh31 |
URO | (HPM) Upper 32 bits Performance-Monitoring Counter 31 |
| User Custom CSRs | |||
| 0xCC0 | lpstart0 |
URO | Hardware Loop 0 Start. Only present if COREV_PULP = 1 |
| 0xCC1 | lpend0 |
URO | Hardware Loop 0 End. Only present if COREV_PULP = 1 |
| 0xCC2 | lpcount0 |
URO | Hardware Loop 0 Counter. Only present if COREV_PULP = 1 |
| 0xCC4 | lpstart1 |
URO | Hardware Loop 1 Start. Only present if COREV_PULP = 1 |
| 0xCC5 | lpend1 |
URO | Hardware Loop 1 End. Only present if COREV_PULP = 1 |
| 0xCC6 | lpcount1 |
URO | Hardware Loop 1 Counter. Only present if COREV_PULP = 1 |
| 0xCD0 | uhartid |
URO | Hardware Thread ID. Only present if COREV_PULP = 1 |
| 0xCD1 | privlv |
URO | Privilege Level. Only present if COREV_PULP = 1 |
| 0xCD2 | zfinx |
URO | ZFINX ISA. Only present if COREV_PULP = 1 & (FPU = 0 | (FPU = 1 & ZFINX = 1)) |
| Machine CSRs | |||
| 0x300 | mstatus |
MRW | Machine Status |
| 0x301 | misa |
MRW | Machine ISA |
| 0x304 | mie |
MRW | Machine Interrupt Enable register |
| 0x305 | mtvec |
MRW | Machine Trap-Handler Base Address |
| 0x320 | mcountinhibit |
MRW | (HPM) Machine Counter-Inhibit register |
| 0x323 | mhpmevent3 |
MRW | (HPM) Machine Performance-Monitoring Event Selector 3 |
| … | … | … | … |
| 0x33F | mhpmevent31 |
MRW | (HPM) Machine Performance-Monitoring Event Selector 31 |
| 0x340 | mscratch |
MRW | Machine Scratch |
| 0x341 | mepc |
MRW | Machine Exception Program Counter |
| 0x342 | mcause |
MRW | Machine Trap Cause |
| 0x343 | mtval |
MRW | Machine Trap Value |
| 0x344 | mip |
MRW | Machine Interrupt Pending register |
| 0x7A0 | tselect |
MRW | Trigger Select register |
| 0x7A1 | tdata1 |
MRW | Trigger Data register 1 |
| 0x7A2 | tdata2 |
MRW | Trigger Data register 2 |
| 0x7A3 | tdata3 |
MRW | Trigger Data register 3 |
| 0x7A4 | tinfo |
MRO | Trigger Info |
| 0x7A8 | mcontext |
MRW | Machine Context register |
| 0x7AA | scontext |
MRW | Machine Context register |
| 0x7B0 | dcsr |
DRW | Debug Control and Status |
| 0x7B1 | dpc |
DRW | Debug PC |
| 0x7B2 | dscratch0 |
DRW | Debug Scratch register 0 |
| 0x7B3 | dscratch1 |
DRW | Debug Scratch register 1 |
| 0xB00 | mcycle |
MRW | (HPM) Machine Cycle Counter |
| 0xB02 | minstret |
MRW | (HPM) Machine Instructions-Retired Counter |
| 0xB03 | mhpmcounter3 |
MRW | (HPM) Machine Performance-Monitoring Counter 3 |
| … | … | … | … |
| 0xB1F | mhpmcounter31 |
MRW | (HPM) Machine Performance-Monitoring Counter 31 |
| 0xB80 | mcycleh |
MRW | (HPM) Upper 32 bits Machine Cycle Counter |
| 0xB82 | minstreth |
MRW | (HPM) Upper 32 bits Machine Instructions-Retired Counter |
| 0xB83 | mhpmcounterh3 |
MRW | (HPM) Upper 32 bits Machine Performance-Monitoring Counter 3 |
| … | … | … | … |
| 0xB9F | mhpmcounterh31 |
MRW | (HPM) Upper 32 bits Machine Performance-Monitoring Counter 31 |
| 0xF11 | mvendorid |
MRO | Machine Vendor ID |
| 0xF12 | marchid |
MRO | Machine Architecture ID |
| 0xF13 | mimpid |
MRO | Machine Implementation ID |
| 0xF14 | mhartid |
MRO | Hardware Thread ID |
Control and Status Register Map (additional CSRs for User mode)
| CSR address | Name | Privilege | Description |
|——————-|—————-|—————|——————————————|
| 0x000 | ustatus | URW | User Status |
| 0x005 | utvec | URW | User Trap-Handler Base Address |
| 0x041 | uepc | URW | User Exception Program Counter |
| 0x042 | ucause | URW | User Trap Cause |
| 0x306 | mcounteren | MRW | Machine Counter Enable |
The following wiki, pages and posts are tagged with
| Title | Type | Excerpt |
|---|
{# nothing on index to avoid visible raw text #}