- Answer
- Numbers Check
- Source Review
- Seeking Help from AI Models
- Summary of Recent Workflows on NLP and RAG
- Details and Insights
Answer
In this book, we will cover the following topics:
- The opportunities, limitations, and risks inherent to various edge AI technologies.
- A framework for analyzing problems and designing solutions using AI and embedded machine learning.
- An end-to-end practical workflow for successfully developing edge AI applications.
- The fundamentals of machine learning.
- The essentials of ML application design.
- Responsible, ethical, and effective AI.
- The most important part of building any kind of application is ensuring that it works correctly in the real world.
- The most fundamental parts of embedded systems.
- The most fundamental parts of machine learning.
- The most fundamental parts of AI.
- The most fundamental parts of edge AI.
- The most fundamental parts of edge AI technologies.
Numbers Check
- {‘fact’: ‘log’, ‘status’: ‘Not Confirmed’, ‘text’: ‘’, ‘page_num’: ‘’, ‘source’: ‘’}
- {‘fact’: ‘log’, ‘status’: ‘Not Confirmed’, ‘text’: ‘’, ‘page_num’: ‘’, ‘source’: ‘’}
- {‘fact’: ‘log’, ‘status’: ‘Not Confirmed’, ‘text’: ‘’, ‘page_num’: ‘’, ‘source’: ‘’}
- {‘fact’: ‘log’, ‘status’: ‘Not Confirmed’, ‘text’: ‘’, ‘page_num’: ‘’, ‘source’: ‘’}
- {‘fact’: ‘log’, ‘status’: ‘Not Confirmed’, ‘text’: ‘’, ‘page_num’: ‘’, ‘source’: ‘’}
- {‘fact’: ‘log’, ‘status’: ‘Not Confirmed’, ‘text’: ‘’, ‘page_num’: ‘’, ‘source’: ‘’}
- {‘fact’: ‘log’, ‘status’: ‘Not Confirmed’, ‘text’: ‘’, ‘page_num’: ‘’, ‘source’: ‘’}
- {‘fact’: ‘log’, ‘status’: ‘Not Confirmed’, ‘text’: ‘’, ‘page_num’: ‘’, ‘source’: ‘’}
- {‘fact’: ‘log’, ‘status’: ‘Not Confirmed’, ‘text’: ‘’, ‘page_num’: ‘’, ‘source’: ‘’}
- {‘fact’: ‘log’, ‘status’: ‘Not Confirmed’, ‘text’: ‘’, ‘page_num’: ‘’, ‘source’: ‘’}
- {‘fact’: ‘11,’, ‘status’: ‘Confirmed’, ‘text’: “ … In the second part of the book, starting in Chapter 11, we’ll use three enologies and standard best practices, so … “, ‘page_num’: ‘7’, ‘source’: ‘aiEdge.pdf’}
- {‘fact’: ‘log’, ‘status’: ‘Not Confirmed’, ‘text’: ‘’, ‘page_num’: ‘’, ‘source’: ‘’}
- {‘fact’: ‘log’, ‘status’: ‘Not Confirmed’, ‘text’: ‘’, ‘page_num’: ‘’, ‘source’: ‘’}
Source Review
- {‘text’: ‘The opportunities limitations and risks inherent to various edge AI technologies A framework for analyzing problems and designing solutions using ‘, ‘match_score’: 0.6282051282051282, ‘source’: ‘aiEdge.pdf’, ‘page_num’: ‘9’, ‘doc_id’: 1, ‘block_id’: 1}
- {‘text’: ‘digging deeper into anything we mentionfrom the fundamentals of machine learning to the essentials of ML application designwell provide lots ‘, ‘match_score’: 0.5512820512820513, ‘source’: ‘aiEdge.pdf’, ‘page_num’: ‘10’, ‘doc_id’: 1, ‘block_id’: 1}
- {‘text’: ‘AI at the Edge Solving RealWorld Problems with Embedded Machine Learning Daniel ‘, ‘match_score’: 0.3717948717948718, ‘source’: ‘aiEdge.pdf’, ‘page_num’: ‘3’, ‘doc_id’: 1, ‘block_id’: 1}
Seeking Help from AI Models
In order to ensure the quality and comprehensiveness of this content, I sought help from AI models, including a locally running model [bling-phi-3-gguf ] and an online assistant [openAI GPT3.5]. Below are the steps and screenshots of the process:
Step 1: Accessing the LMSYS Chatbot Arena
Step 2: Choosing Models to Compare
Step 3: Interaction with Models
Upcomign Next I will dockerize llm services I can deploy anywhere.
Summary of Recent Workflows on NLP and RAG
Learning Curves of LLM Models
Over the past few weeks, I have been closely monitoring and analyzing the learning curves of various LLM (Large Language Model) models. This involved comparing their performance on different tasks and understanding the nuances of their learning behaviors.
Here are some visual representations of the CLI and UI used for these analyses:
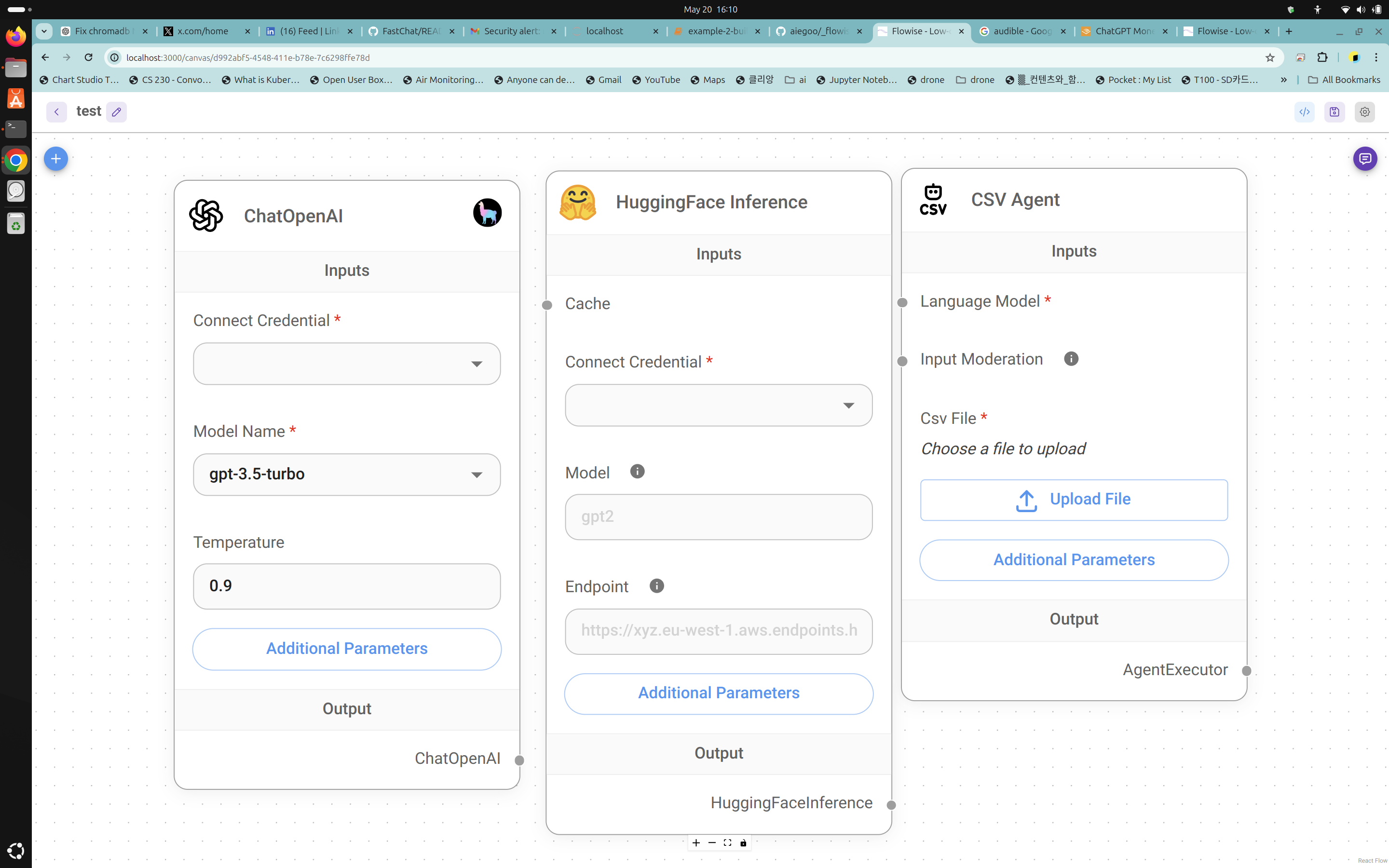
State of the Art Project: Pronunciation Coach
One of the significant projects I have been working on is a pronunciation coach application. This tool leverages state-of-the-art NLP and RAG (Retrieval-Augmented Generation) techniques to assist users in improving their pronunciation skills.
Below is a sample video demonstrating the functionality of the pronunciation coach:
The application is designed to provide real-time feedback and suggestions, making it an invaluable resource for language learners.
Details and Insights
- LLM Learning Curves: The learning curves indicate that the models improve significantly with increased data and iterations. However, fine-tuning and domain-specific adjustments are crucial for optimal performance.
- Pronunciation Coach Development: The project involved integrating various APIs and leveraging advanced NLP techniques to ensure accurate and helpful feedback for users. The use of RAG techniques enabled the system to provide more contextual and relevant suggestions.
The book discusses various types of algorithms by their functionality. Here are some key topics along with brief explanations and examples for each:
1. Anomaly Detection
Anomaly detection algorithms identify rare events or patterns that differ significantly from the majority of the data. This is crucial in applications like fraud detection, network security, and fault detection.
Example: Isolation Forest in Python
from sklearn.ensemble import IsolationForest
import numpy as np
# Sample data: normal data points with some anomalies
X = np.array([[10, 10], [11, 10], [10, 11], [12, 12], [50, 50], [60, 60]])
# Fit the model
clf = IsolationForest(random_state=42).fit(X)
predictions = clf.predict(X)
print(predictions) # -1 for anomalies, 1 for normal data points
2. Regression
Regression algorithms predict a continuous outcome variable based on one or more predictor variables. Commonly used in forecasting and risk assessment.
Example: Linear Regression in Python
from sklearn.linear_model import LinearRegression
import numpy as np
# Sample data
X = np.array([[1], [2], [3], [4], [5]])
y = np.array([1, 4, 9, 16, 25])
# Fit the model
model = LinearRegression().fit(X, y)
print(model.predict([[6]])) # Predicting the value for X=6
3. Classification
Classification algorithms categorize data into predefined classes. Widely used in spam detection, image recognition, and medical diagnosis.
Example: Logistic Regression in Python
from sklearn.linear_model import LogisticRegression
import numpy as np
# Sample data: features and labels
X = np.array([[0.5], [1.5], [3.5], [4.5], [6.5]])
y = np.array([0, 0, 1, 1, 1])
# Fit the model
model = LogisticRegression().fit(X, y)
print(model.predict([[2.5]])) # Predicting the class for X=2.5
4. Clustering
Clustering algorithms group similar data points together. Useful in market segmentation, image compression, and pattern recognition.
Example: K-Means Clustering in Python
from sklearn.cluster import KMeans
import numpy as np
# Sample data
X = np.array([[1, 2], [1, 4], [1, 0],
[10, 2], [10, 4], [10, 0]])
# Fit the model
kmeans = KMeans(n_clusters=2, random_state=0).fit(X)
print(kmeans.labels_) # Cluster labels for each data point
print(kmeans.cluster_centers_) # Coordinates of cluster centers
5. Recommendation Systems
Recommendation systems predict user preferences and suggest items accordingly. Commonly used in e-commerce and streaming services.
Example: Collaborative Filtering in Python (using Surprise library)
from surprise import Dataset, Reader, SVD
from surprise.model_selection import train_test_split
from surprise import accuracy
# Load the movielens-100k dataset
data = Dataset.load_builtin('ml-100k')
# Sample data
trainset, testset = train_test_split(data, test_size=0.25)
# Use the SVD algorithm
algo = SVD()
algo.fit(trainset)
# Make predictions and compute accuracy
predictions = algo.test(testset)
print(accuracy.rmse(predictions))
These examples provide a high-level overview of how to implement different types of algorithms based on their functionality. Each algorithm serves specific purposes and is selected based on the problem requirements and the nature of the data.
Sure, here’s the content formatted in Markdown for your documentation site:
## Algorithm Types by Functionality
### 1. Anomaly Detection
Anomaly detection algorithms identify rare events or patterns that differ significantly from the majority of the data. This is crucial in applications like fraud detection, network security, and fault detection.
#### Example: Isolation Forest in Python
```python
from sklearn.ensemble import IsolationForest
import numpy as np
## Sample data: normal data points with some anomalies
X = np.array([[10, 10], [11, 10], [10, 11], [12, 12], [50, 50], [60, 60]])
# Fit the model
clf = IsolationForest(random_state=42).fit(X)
predictions = clf.predict(X)
print(predictions) # -1 for anomalies, 1 for normal data points
2. Regression
Regression algorithms predict a continuous outcome variable based on one or more predictor variables. Commonly used in forecasting and risk assessment.
Example: Linear Regression in Python
from sklearn.linear_model import LinearRegression
import numpy as np
# Sample data
X = np.array([[1], [2], [3], [4], [5]])
y = np.array([1, 4, 9, 16, 25])
# Fit the model
model = LinearRegression().fit(X, y)
print(model.predict([[6]])) # Predicting the value for X=6
3. Classification
Classification algorithms categorize data into predefined classes. Widely used in spam detection, image recognition, and medical diagnosis.
Example: Logistic Regression in Python
from sklearn.linear_model import LogisticRegression
import numpy as np
# Sample data: features and labels
X = np.array([[0.5], [1.5], [3.5], [4.5], [6.5]])
y = np.array([0, 0, 1, 1, 1])
# Fit the model
model = LogisticRegression().fit(X, y)
print(model.predict([[2.5]])) # Predicting the class for X=2.5
4. Clustering
Clustering algorithms group similar data points together. Useful in market segmentation, image compression, and pattern recognition.
Example: K-Means Clustering in Python
from sklearn.cluster import KMeans
import numpy as np
# Sample data
X = np.array([[1, 2], [1, 4], [1, 0],
[10, 2], [10, 4], [10, 0]])
# Fit the model
kmeans = KMeans(n_clusters=2, random_state=0).fit(X)
print(kmeans.labels_) # Cluster labels for each data point
print(kmeans.cluster_centers_) # Coordinates of cluster centers
5. Recommendation Systems
Recommendation systems predict user preferences and suggest items accordingly. Commonly used in e-commerce and streaming services.
Example: Collaborative Filtering in Python (using Surprise library)
from surprise import Dataset, Reader, SVD
from surprise.model_selection import train_test_split
from surprise import accuracy
# Load the movielens-100k dataset
data = Dataset.load_builtin('ml-100k')
# Sample data
trainset, testset = train_test_split(data, test_size=0.25)
# Use the SVD algorithm
algo = SVD()
algo.fit(trainset)
# Make predictions and compute accuracy
predictions = algo.test(testset)
print(accuracy.rmse(predictions))
```
a structured and clear presentation of the different types of algorithms by functionality, complete with examples in Python.
Conclusion
These projects have provided deep insights into the capabilities and limitations of current NLP technologies. Moving forward, the focus will be on refining these models and enhancing the pronunciation coach’s features based on user feedback and further research.
The following wiki, pages and posts are tagged with
| Title | Type | Excerpt |
|---|---|---|
| Weather app from firebase | post | Sunday-weather-app, open weather api |
| Exploring Jetson Nano in AIoT Applications | page | Jetson Nano serves as a potent platform for Edge AI applications, supporting popular frameworks like TensorFlow, PyTorch, and ONNX. Its compact form factor a... |
| 🔭sensor detection | page | RealSense with Open3D |
| AIOT Portfolio: From Edge AI to Autonomous Systems | post | A comprehensive showcase of my AIOT (AI + IoT) projects demonstrating the fusion of artificial intelligence with Internet of Things technologies. From autono... |
{# nothing on index to avoid visible raw text #}