firstIn2025, for what it's worth
AI tutor agent platform
강의 데이타, 교육학 이론, AI 특화 기술을 접목해 수강생생의 학습 효과를 극대화 하는 콘텐츠 생성
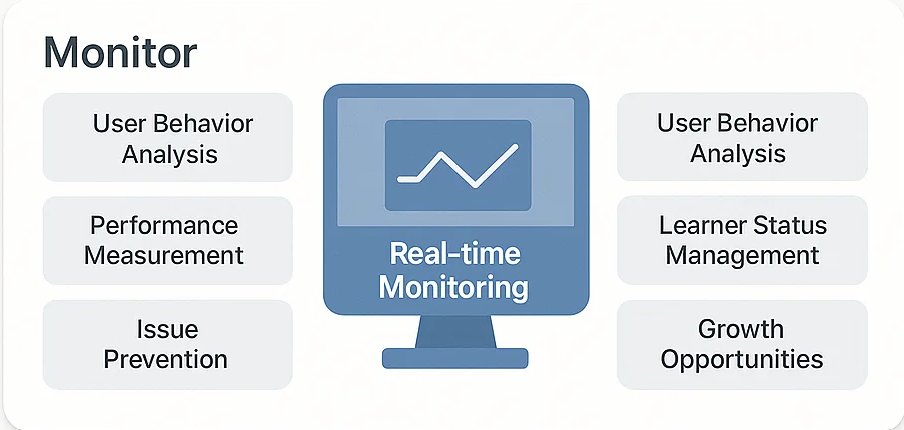
운영관리서비스 사용자 대화 및 학습 데티터를 분석하여 서비스 개선 인사이트를 얻고, 기업별 맟춤 데이터 연동과 커스터마이징 지원
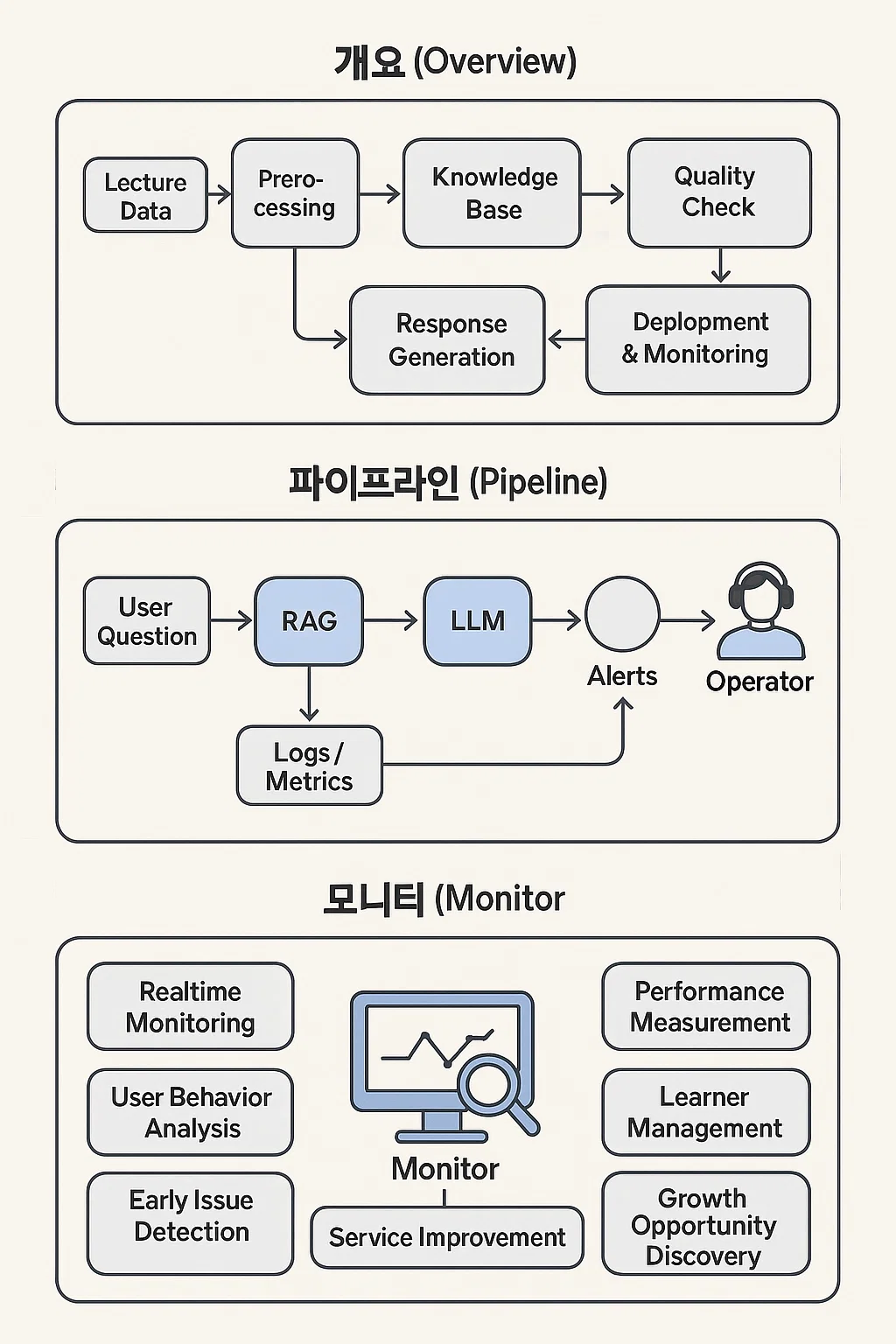
- 실시간 모니터링
- 사용자 행동 분석
- 성과 측정
- 학습자 현황 관리
- 문제 조기 해결
- 성장 기회 발굴
- 서비스 품질 향상
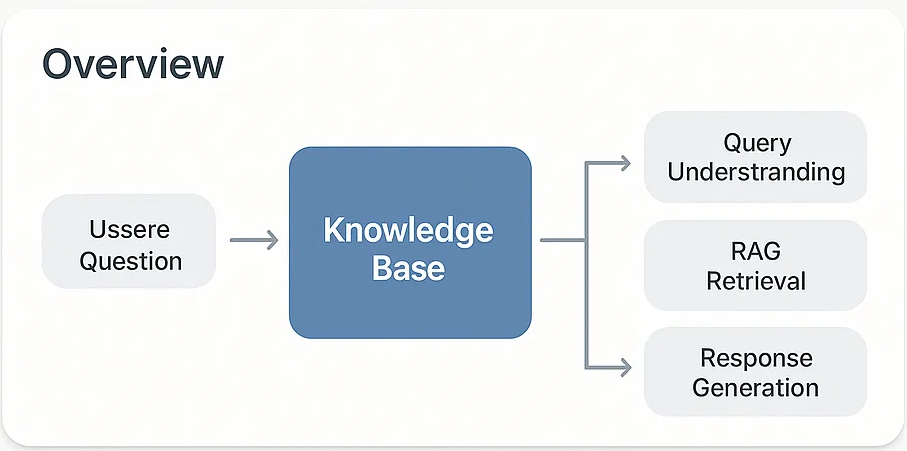
강의 데이터 전처리 학습 질문 유사 자료의 검색 매칭 답변 품질 검증 및 보정
오늘 한 일 요약
배포
voice-ai, likelion application 공개 및 링크 정리
수정
Gemfile/lock, _config, include 문법, 이미지 경로
자동화
createwiki 경로 수정, 테이블 자동 생성
환경
JDK/rcc 경로 정리, Actions 빌드 안정화
플랫폼 아키텍처(개요)
flowchart LR
A[강의 데이터] --> B[전처리/정제]
B --> C[지식베이스 구축 (벡터/메타)]
C --> D[질의 이해(NLU)]
D --> E[RAG 검색/매칭]
E --> F[응답 생성(LLM)]
F --> G[품질 검증·보정]
G --> H[배포/대화 파이프라인]
H --> I[모니터링/피드백]
I --> B
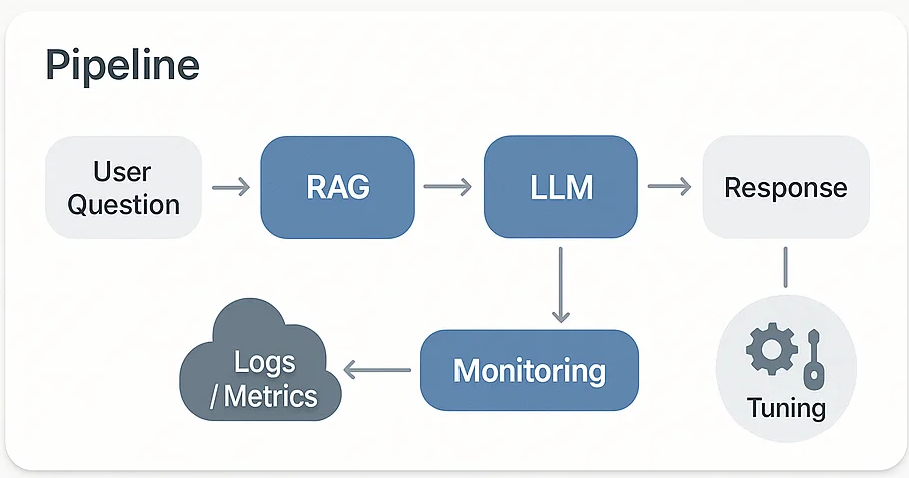
운영/모니터링 플로우
sequenceDiagram
participant U as 사용자
participant S as 서비스
participant M as 모니터링
participant O as 운영자
U->>S: 질문/대화
S->>S: RAG + LLM 응답 생성
S-->>M: 로그/지표 전송
M-->>O: 알림(지연/오류/품질저하)
O->>S: 설정 튜닝/리디플로이
핵심 지표(KPI)
| 항목 | 정의 | 목표 |
|---|---|---|
| 응답 지연 | 사용자 요청→응답 완료 | p95 < 2.0s |
| 정확도 | 정답/가이드 일치율 | > 92% |
| 실패율 | 5xx/타임아웃 비율 | < 0.5% |
| 유지율 | 7일 재방문 | > 35% |
갤러리
아래 경로에 이미지를 저장하면 자동으로 표시됩니다.
- 폴더: /wiki-img/2025/diary/38th/
Here’s an in-depth breakdown of how Rasa, Ollama LLMs, LangChain, RAG, and multimodal models like LLaVA and MiniGPT-4 can interact in a layered architecture—from input to response generation—so you can build an advanced assistant system with:
- Multimodal capabilities (image + text)
- Offline/local LLM support
- Retrieval-augmented memory
- Intent and dialogue logic
- Smart assistants in Korean or multilingual environments
🔁 High-Level System Flow: Interaction Between All Components
+------------------------+
| User Input (Text / |
| Voice / Image / UI) |
+-----------+------------+
|
+------------------------------+------------------------------+
| |
[Text Intent / Dialogue] [Multimodal Input]
| |
+------v------+ +--------v--------+
| RASA NLU | | LLaVA / MiniGPT-4 |
| (Intent + |<--------------------------------------------| (Image QA + Captioning)
| Slot Filler| +------------------+
+------+------+
|
|
v
+---------------+ +-------------------------------------+
| RASA CORE | <-----------> | Action Server (Python logic) |
| Dialogue Mgmt | | (DB Lookup, API Call, File Parser) |
+-------+-------+ +-------------------+----------------+
| |
| |
v v
+---------------+ +----------------------------+
| LLM via Ollama | | LangChain / LlamaIndex |
| (e.g., Mistral |<------ RAG Input ------| - Vector DB (FAISS, Chroma) |
| or Phi-2) | | - Retrieval & Chunking |
+---------------+ +-----------------------------+
^ |
| |
+------------------+-------------------------------+
|
[RAG + LLM Answers Back to User]
📚 Example Use Cases and Interactions
| Scenario | Tools Involved | Flow |
|---|---|---|
| “보여준 표에서 가장 큰 수치는?” (Ask about chart image) | MiniGPT-4 | Image → MiniGPT-4 → Caption/QA → Return |
| “이 파일 요약해줘” (Upload PDF) | LangChain + Ollama | PDF → split + embed → retrieve relevant → answer via LLM |
| “지하철 언제 끊겨?” (Intent + API Call) | Rasa → Action Server | Intent → API request → response |
| “이건 무슨 단어야?” (Pronunciation + Vocabulary) | Rasa + TTS + Whisper | Intent → Pronunciation check → feedback |
| “이전 대화 다시 보여줘” (Context memory) | LangChain memory or Redis | Retrieve chat history + generate response |
| “이 이미지에서 위험 요소 찾아줘” | LLaVA | Image input → object detection/QA → highlight result |
| “나는 영어보다 한국어 발음이 어려워” | Ollama (Mistral multilingual) | User feedback → generate personalized study plan |
🔧 Deployment Options
| Setup | Description |
|---|---|
| Docker Compose | Bundle Ollama, Rasa, LangChain, vector DB, and image QA into a self-contained offline assistant. |
| Local venv | Lightweight, better for dev or Raspberry Pi class hardware. |
| Remote Frontend | SPA built with React or SvelteKit talking to Flask/FastAPI gateway that wraps these services. |
| On-Device App | Package via Tauri or Electron for Linux/Windows. |
✅ Suggested Next Steps
Coming UP Next:
- Use
Ollamato host your LLM base (Mistral or Phi-2). - Use
LangChainto enable document retrieval (FAISS+ PDF ingestion). - Add
RASAto handle structured conversations with NLU and fallback to LLM when open-ended. - Connect
MiniGPT-4/LLaVAfor multimodal support (charts, screenshots). - Use Whisper for voice and ASR + TTS with Coqui or Silero.
- Add progress tracking, memory, and feedback loops (e.g., for learners or daily reports).
a real working Docker Compose config to integrate RASA + Ollama + LangChain + vector DB + Whisper
The following wiki, pages and posts are tagged with
| Title | Type | Excerpt |
|---|
{# nothing on index to avoid visible raw text #}