Project post
Click to open
I need an experienced data scientist or AI specialist to assist with evaluating a Korean dataset using OpenAI API calls. my goal is to set up a good testing template I can repeat
Key Aspects:
- Inference Speed: Achieving a balance of optimal inference speed is vital for this project. The desired inference speed for the evaluation stands at a moderate level when considering 2000 users.
- Total Processing Accuracy: I’m looking to ensure the total processing accuracy of this evaluation is high.
- TPA (Total Processing Accuracy): Aspects of TPA are crucial for this project; we aim for a balanced importance between total processing accuracy and inference speed. (<1 /s is imperative)
- Implement this on a shared googleColab or Jupyternotebook for on-demand use of the application
Ideal Skills and Experience:
- Proficiency in Korean language and understanding of language nuances.
- Previous experience with data evaluation using OpenAI API calls.
- Proven track record in achieving optimal inference speeds for data processing.
- Demonstrated ability to balance and optimize processing accuracy alongside inference speed.
- Strong communication skills to provide regular updates on the project’s progress.
refer to this documentation; https://python.langchain.com/docs/langsmith/walkthrough/
request for access to the example document where all the testing data and instructions should be maintained and updated; https://docs.google.com/document/d/16GFgABbbnH7RXgL56SXNu41xRspstgtVcy0TQxmwd-A/edit?usp=drive_link
API example; https://api-engtoprod.meta-wedit.com/api-docs#/USER%20API/UsersController_perpectConversation
deliverables; The test procedure as described and per our discussion to the format of the sample google doc. Set of scripts for JMeter configs, python for accuracy and inference test. (hopefully Colab) A working PC implementation to run the test, on a machine and VM (dockerized) to replicate the same testing environment repeatedly. A full documentation of test procedure, steps, screenshots, reference links, of running tests, and setups.
revised requirments
Key responsibilities:
- Conducting performance tests on LLMs.
- Analysing the results and comparing them to identify the best performing system.
- Providing recommendations on how to optimize the performance of the chosen LLM.
- Set up a local testing environment (chatbot, playground dashboard, Jmeter 5.5)
- Set up a cloud server (API server)
- Google Colab, Jupyter Notebook
- All configuration, test scripts in python, bash and exe)
- Dockerized images for future implementation
- Our Korean dataset of 20,000 published to HuggingFace workspace based on an existing Korean dataset
- documentation 1. testing items/procedures 2. instructions, manuals of this project.
Models to consider:
llama3-8b-8192
text-davinci-003
Mixtral 8x22b
Whisper
Reference:
https://pf7.eggs.or.kr/aigenerative_overview.html
Sample testing items (send me a permission request with your name plz)
https://docs.google.com/document/d/16GFgABbbnH7RXgL56SXNu41xRspstgtVcy0TQxmwd-A/edit
Project resources
googleDrive
overview
| TestItems | uconc | q&aDataset / hfConverse | hfQ&A / hfQ&A2 | projectBlog | hfQ&A3
datasets
hfDataset check under metrics for various testing items
HuggingFace Korean dataset 일상대화 : 다양한 질의답1 : 네이버 지식인 질의답 : 다양한 질의답2 :

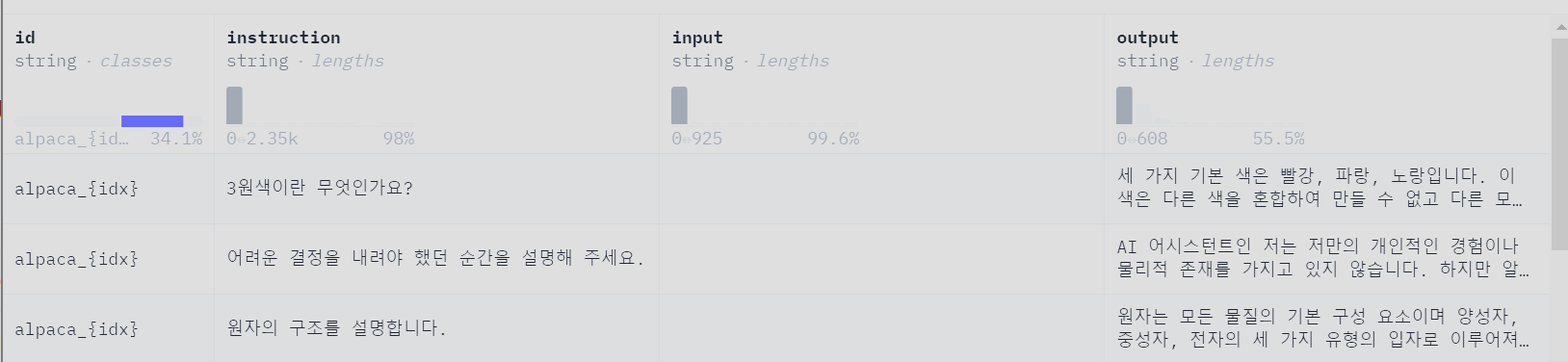

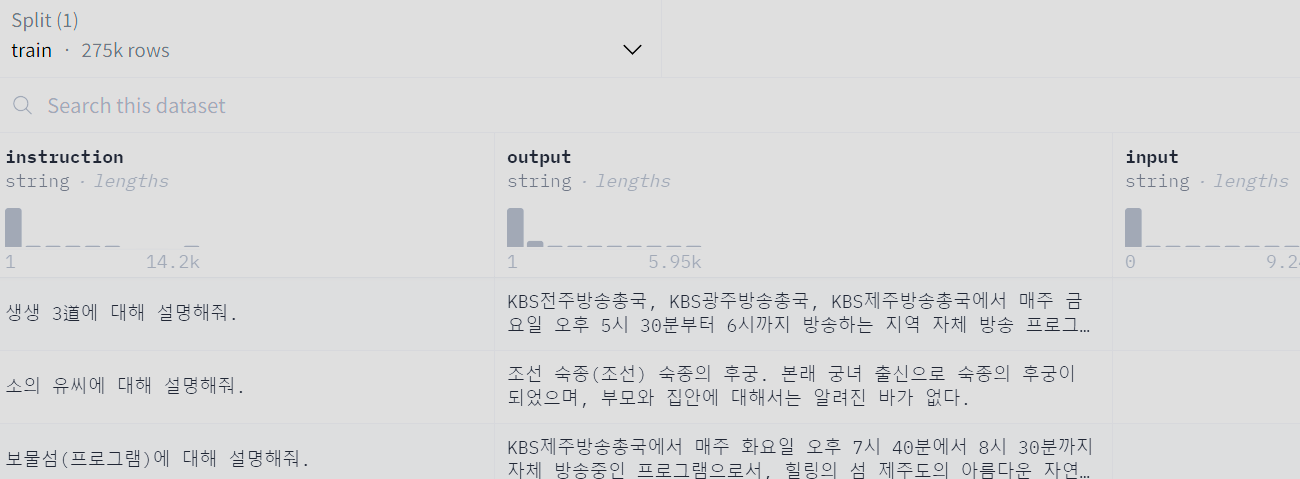
다양한 질의답2 : https://huggingface.co/datasets/unoooo/alpaca-korean
our dataset
other models
Models to consider: llama3-8b-8192 text-davinci-003 Mixtral 8x22b Whisper
AWS server
WindowsServer port: on MS RemoteDesktop itsInstance accessible only via aws console

Windows Sever
Setup, Jmeter
Creds and IP
mlOps
[JupyterNotebook]
LLM candidates
| Models to consider: | llama3-8b-8192 | text-davinci-003 | Mixtral 8x22b | Whisper |
misTral for mistral llm api docs
gorqCloud and playgroundConsole
ncSoftVaroq Korean LLM by NCSoft based varco llm and kendra
gpt4all locally hosted chatbot opensource.
Day 1, day2, day 3, day 4, day 5, day 6
Click to open
Day1
- Shared creds with freelancers
- Task assigned among the group
- AWS WindowServer instance
- Completed the testing pc on the server Day2
- Application Server
- API server
- Lib install and setup
- Download llm models
- Write scripts Day3 (today)
- Write scripts using quantization of llms models
- setup the application server.
- pythong library issue
- model candidates per quantization
- flask app installed
performance test
metrics
perplexity, accuracy, wer
Click to open
├───metrics
│ ├───accuracy
│ ├───bertscore
│ ├───bleu
│ ├───bleurt
│ ├───cer
│ ├───chrf
│ ├───code_eval
│ ├───comet
│ ├───competition_math
│ ├───coval
│ ├───cuad
│ ├───exact_match
│ ├───f1
│ ├───frugalscore
│ ├───glue
│ ├───google_bleu
│ ├───indic_glue
│ ├───mae
│ ├───mahalanobis
│ ├───matthews_correlation
│ ├───mauve
│ ├───mean_iou
│ ├───meteor
│ ├───mse
│ ├───pearsonr
│ ├───perplexity
│ ├───precision
│ ├───recall
│ ├───roc_auc
│ ├───rouge
│ ├───sacrebleu
│ ├───sari
│ ├───seqeval
│ ├───spearmanr
│ ├───squad
│ ├───squad_v2
│ ├───super_glue
│ ├───ter
│ ├───wer
│ ├───wiki_split
│ ├───xnli
│ └───xtreme_s
`
The following wiki, pages and posts are tagged with
| Title | Type | Excerpt |
|---|---|---|
| Weather app from firebase | post | Sunday-weather-app, open weather api |
| Exploring Jetson Nano in AIoT Applications | page | Jetson Nano serves as a potent platform for Edge AI applications, supporting popular frameworks like TensorFlow, PyTorch, and ONNX. Its compact form factor a... |
| 🔭sensor detection | page | RealSense with Open3D |
| AIOT Portfolio: From Edge AI to Autonomous Systems | post | A comprehensive showcase of my AIOT (AI + IoT) projects demonstrating the fusion of artificial intelligence with Internet of Things technologies. From autono... |
{# nothing on index to avoid visible raw text #}